Linux内存布局与C的内存布局
使用C作为开发语言,最重要的就是指针,而指针就是一个指向内存的索引。理解Linux和C程序的内存布局是深入理解C语言开发和程序运行等原理的一个必要条件。
Linux内存布局
虚拟内存
虚拟内存是操作系统对于内存的抽象,为进程对于内存的使用提供了易于使用的接口,将多进程使用内存的复杂性留给操作系统和硬件,内存使用者则可以以独占内存的方式进行开发使用。
虚拟内存需要对应到实际的物理内存上才可以真正地分配使用,我们很容易(其实是站在设计好的前提下开上帝视角才容易)想到可以建立一个虚拟内存与物理内存的映射表,将虚拟的内存地址与物理内存对应起来,进程通过虚拟内存寻址、使用,实际的指令通过物理内存执行。CPU中的内存管理单元(Memory Management Unit,MMU)负责处理虚拟内存地址向物理地址的翻译工作。
分页和页表
32位系统中,地址的长度为32位,4字节;而在64位系统中,理论上地址的长度是64位,8字节,但是由于现在基本上用不到这么多的寻址空间,一般的64位CPU架构设计中都只使用了40位(4x位)来作为地址位,因此64位系统中也只采用了40位作为地址的长度,也就是5字节。一般在操作系统中,对于内存的最小标识单位为字节,也就是可以用32位表示字节地址,对应2^32Byte(4GB)内存;64位系统中,可以寻址40位对应2^40Byte(1TB)内存。
操作系统需要对进程实现从虚拟内存到物理内存的映射,维护一个内存映射表,虚拟地址->物理地址,以32位系统为例,在极端情况下需要维护一个4GB地址->4GB地址的大映射表。解决这个问题,就要引入分级的方式,也就是内存的分页。操作系统以2^n作为一个内存页的大小,将内存分页,此时地址可以分为两部分,前一部分表示内存的页标号,后一部分表示页内的偏移量。
其实写这里的时候我产生了一些困惑,即使采用了分页,维护的映射表大小难道不是一样的吗。后来又经过思考,这里的主要解决问题是:在运行大内存的进程时,物理内存是不够用的,这种情况下,暂时不用的部分写入磁盘中,活跃的部分取到内存中,因此需要维护一个很大的内存映射表。而分页就是解决这个问题的,就是将内存不再以Byte为基本单位,而是以2^nByte的页为基本单位,内存主要维护一个虚拟内存页->物理内存页的页表即可。而具体的地址,又可以通过页内的偏移量来查找。此时的页表就是远小于地址映射表的,相当于除以页的大小2^n。这样就说通了,同理也就可以产生分级页表这样进一步分隔的方法,也很容易想到采用hash等方式进行维护。
而分页的另一个重要的优势,在于以页为单位进行块内存的分配,利于离散的内存分配,提高内存的利用率并减少内存分配的时间开销。
至于缺页中断等问题,本文就不再探讨,可以在操作系统原理中进一步探究,这里仅为了理清内存布局简单提一下。
进程的内存
操作系统就是用户与硬件之间的一个过渡层,将硬件的复杂性屏蔽掉,并提供一些可以直接使用的接口。在内存分配方面,操作系统为进城提供了虚拟内存,使得进程可以认为自己是独占全部内存的,每一个进程都可以看作自己拥有全部的内存空间。
进程的内存布局
C的可执行程序在未执行时占用的存储空间分布如下,只包含了程序的代码部分和静态数据段部分。在未执行时,未初始化变量只存在名字与大小,并不真正占用空间。

加载过程与进程的内存布局如下图所示,exec进程将程序的代码段和初始化变量加载到内存中,并将未初始化变量初始化为0。
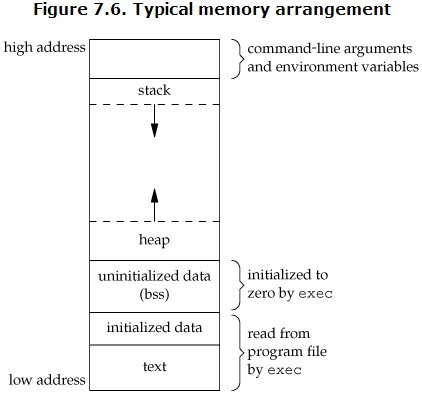
而加载到内存中的进程内存空间分布如下,从内存空间的低地址开始,存储空间的区域分别为保留区域、代码段、只读数据段,读写数据段、堆、栈、内核空间。
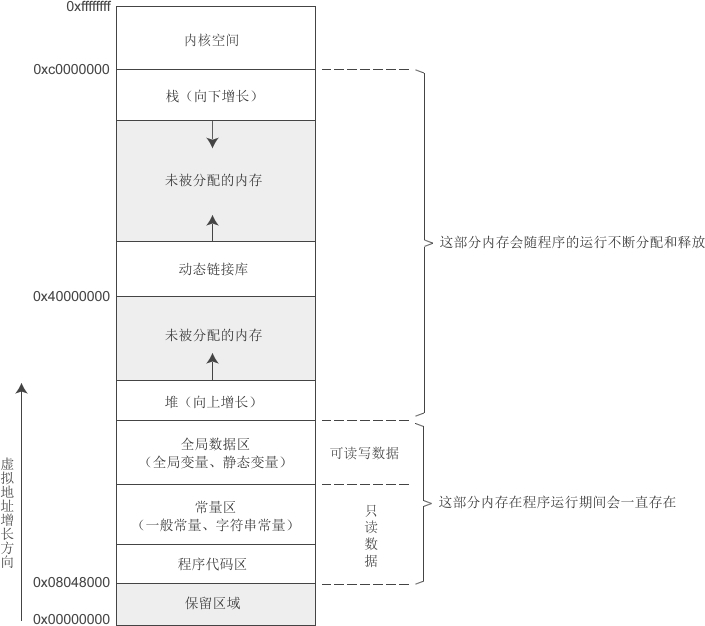
保留区域
以4G内存32位寻址空间为例,0x08048000以下的地址是保留区域,这部分用于存储一些C库,动态加载器如ld.so和vdso等的映射地址。//TODO:需要进一步确认
静态区域
一下两个部分是静态区域,在进程中一直存在。
只读区域
这部分的权限是RO,即只读权限,包含了程序的二进制代码段(.Text),和只读数据区(RO data)。只读数据区包含程序中的全局常量和字符串常量。
读写区域
这部分的权限是RW,即可读可写权限。这部分包含未初始化变量和初始化变量BSS段(BSS,Block Started by Symbol。未初始化变量包括全局变量和静态变量(static修饰)。
动态区域
动态区域的内存会随着进程的运行不断地进行分配和释放。
堆
堆一般由开发者进行分配和释放,分配方式类似于链表,维护一个内存块的链表。手动分配的内存要注意释放,否则会出现内存泄漏。堆是自底向上增长的。
栈
栈是由编译器自动进行分配和释放的,函数内部使用的变量、函数的参数以及返回值将使用栈空间。栈是自顶向下增长的。栈的分配是按块直接分配的,如果剩余空间足够,就直接进行分配,否则出现栈溢出错误。栈的分配与数据结构中栈的概念类似,遵循FILO原则。在函数调用时,第一个进栈的是主函数中函数调用后的下一条指令的地址,然后是函数的各个参数(在大多数的C编译器中,参数是从右往左入栈的),然后是局部变量。函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,读取主函数中的下一条指令。多层嵌套的函数逐级进行入栈出栈。
内存映射段
堆和栈的空间并不是直接连接的,中间存在一段空间,并且由于系统对于内存的保护机制,存在随机长度的偏移量。在这段空间中,存在内存映射段。内核将文件的内容直接映射到内存。进程可以通过Linux的mmap()系统调用或者Windows的CreateFileMapping()/MapViewOfFile()请求这种映射。内存映射是一种方便高效的文件I/O方式,所以它被用来加载动态库。创建一个不对应于任何文件的匿名内存映射也是可能的,此方法用于存放程序的数据。在Linux中,如果通过malloc()请求一块大内存,C运行库将会创建这样一个匿名映射而不是使用堆内存。大内存意味着比MMAP_THRESHOLD(缺省值128KB,可以通过mallocp()调整)还大。
从内存空间的低地址开始,向上增长一次为保留区域,程序代码段(.TEXT),
内核空间
内核空间是所有进程共享的,归操作系统所有,进程从内核空间获取命令行参数和环境变量信息。
查看内存布局
进程的内存布局可以通过查询进程pid对应的maps文件来查看,即文件/proc/pid/maps。nm 命令显示关于指定 文件中符号的信息, nm 命令缺省情况下报告十进制符号表示法下的数字值。objdump是显示关于目标文件的各种信息的命令行程序,可用作反汇编器来以汇编代码形式查看可执行文件。nm和objdump都可以查看程序的符号表,从而查看程序静态的内存分布情况。